Este es un texto difícil, poco claro, poco conclusivo (a quien le de flojera el asunto estadístico puede saltar hasta el final y leer algunas conclusiones).
Creo que se debe más a mi necesidad de entender que de explicar. Podría escribir sobre asuntos más personales, más emocionales digamos, que de esos sobran después del 2 de julio. Los por qués itinerantes. ¿Por qué voté por López Obrador? ¿Por qué quizás no lo haría nuevamente? ¿Por qué, entre el pecho y la cabeza, se me vuelven a atorar algunas dudas? ¿Por qué escucho el discurso de López Obrador y siento esta pesadéz estomacal? ¿Por qué los discursos excedidos de acusasiones y carentes de argumentos convincentes? ¿Por qué me irrita la cobardía de unas manos que en la madrugada destruyen la opinión de quienes, equivocados o no, manifiestan sus sospechas sobre el proceso electoral? ¿Por qué coños estoy yo a las 12:34 a.m. pensando y escribiendo estas cosas?
Para mi fortuna creo que soy todavía el único lector de mi blog, así que eso me evalentona lo suficiente para seguirle. Van dos prevenciones de por medio. En primer lugar, no soy experto en estadística, mucho menos en teoría de probabilidades. En segundo lugar, los datos aquí presentados, no son propios, pertenecen a una página generada por el Dr. Luis Mochán, investigador y físico de la UNAM, quien en un tono, me parece, harto prudente, presenta algunas cuestiones interesantes respecto al comportamiento de los datos generados mediante el PREP y el Conteo Distrital.
Dicho esto, empecemos (para ver mejor las gráficas, den click sobre ellas).
Primero el PREP.
Me salto las gráficas iniciales y empiezo por la figura 5 que grafica la distribución en la diferencia de votos entre Calderón y AMLO contra la acumulación de actas acumuladas: Aquí lo peculiar es el cambio abrubto entre tendencias. Por supuesto, esperamos fluctuaciones dado el timing de arribo de las actas a lo largo de todo el proceso de conteo, no necesariamente estos cortes tan dramáticos. ¿Se parece esto a lo que uno esperaría? Primero debemos señalar que Madrazo se encuentra ausente de esta medición. Segundo, no sabemos que tanto se parece esto a una distribución esperada.
Aquí lo peculiar es el cambio abrubto entre tendencias. Por supuesto, esperamos fluctuaciones dado el timing de arribo de las actas a lo largo de todo el proceso de conteo, no necesariamente estos cortes tan dramáticos. ¿Se parece esto a lo que uno esperaría? Primero debemos señalar que Madrazo se encuentra ausente de esta medición. Segundo, no sabemos que tanto se parece esto a una distribución esperada.
La segunda gráfica muestra la acumulación de votos contra la acumulación de actas procesadas hasta 70,000:
 Aquí el tema es el comportamiento de extrapolaciones. Lo que hacen es ver el comportamiento esperado hacia atrás y hacia adeñante de la acumulación de votos con base en el comportamiento observado en el rango de 10 mil a 20 mil actas procesadas. En el caso de Calderón el ajuste es casi perfecto entre la línea de extrapolación y la línea observada. En el caso de Madrazo hay un pequeño sesgo positivo de la línea observada, esto significa simplemente que Madrazo acumuló más votos de 'lo esperado' hacia el final del proceso, lo que se ajusta a la intuición del voto rural priísta que siempre llega un poco más tarde. El caso de AMLO es el más interesante. En ambos lados la línea real y la línea de extrapolación no se ajusta. Hacia la derecha la línea real tiene un sesgo negativo, eso bien puede decir que las ganancias reales de Madrazo fueron las pérdidas 'no esperadas' de AMLO. Lo notorio es hacia la izquiera, la de AMLO es la única extrapolación hacia el origen que NO CORTA EN CERO, sino en -126, 135 votos. ¿Esto que significa? una posibilidad es que contrario a lo esperado, las últimas casillas reducieron su apoyo a AMLO, y esto sucedió además monotónicamente, o bien, como lo frasea el profesor Mochán: " En un escenario de mucha especulación sobre conspiraciones, estos datos podrían interpretarse de la siguiente manera: Pareciera haberse restado un voto a favor de AMLO por cada una de las 130,000 casillas durante la acumulación de los resultados. Seguramente, se podrían encontrar otras explicaciones. Será interesante saber por qué el voto de las primeras 10,000 casillas fue tan distinto al de las 60,000 casillas subsiguientes..." Demasiada especulación supongo. Pero sigamos.
Aquí el tema es el comportamiento de extrapolaciones. Lo que hacen es ver el comportamiento esperado hacia atrás y hacia adeñante de la acumulación de votos con base en el comportamiento observado en el rango de 10 mil a 20 mil actas procesadas. En el caso de Calderón el ajuste es casi perfecto entre la línea de extrapolación y la línea observada. En el caso de Madrazo hay un pequeño sesgo positivo de la línea observada, esto significa simplemente que Madrazo acumuló más votos de 'lo esperado' hacia el final del proceso, lo que se ajusta a la intuición del voto rural priísta que siempre llega un poco más tarde. El caso de AMLO es el más interesante. En ambos lados la línea real y la línea de extrapolación no se ajusta. Hacia la derecha la línea real tiene un sesgo negativo, eso bien puede decir que las ganancias reales de Madrazo fueron las pérdidas 'no esperadas' de AMLO. Lo notorio es hacia la izquiera, la de AMLO es la única extrapolación hacia el origen que NO CORTA EN CERO, sino en -126, 135 votos. ¿Esto que significa? una posibilidad es que contrario a lo esperado, las últimas casillas reducieron su apoyo a AMLO, y esto sucedió además monotónicamente, o bien, como lo frasea el profesor Mochán: " En un escenario de mucha especulación sobre conspiraciones, estos datos podrían interpretarse de la siguiente manera: Pareciera haberse restado un voto a favor de AMLO por cada una de las 130,000 casillas durante la acumulación de los resultados. Seguramente, se podrían encontrar otras explicaciones. Será interesante saber por qué el voto de las primeras 10,000 casillas fue tan distinto al de las 60,000 casillas subsiguientes..." Demasiada especulación supongo. Pero sigamos.
Me salto varias gráfica y llego a otro grupo interesante. Aquí se presentan los histogramas correspondientes a la frecuencia en el número de veces que un candidato obtuvo determinado número de votos. Esto es, por ejemplo en cuántas casillas Madrazo obtuvo 10 votos, en cuántas 11, en cuántas 12...Empecemos entonces con Madrazo:
 La distribución del voto por madrazo por acta es impecable, de "libro de texto" nos dice el profesor. Tiene 0 casillas con 0 votos, y se comporta normalmente. Ahora, la de AMLO:
La distribución del voto por madrazo por acta es impecable, de "libro de texto" nos dice el profesor. Tiene 0 casillas con 0 votos, y se comporta normalmente. Ahora, la de AMLO:
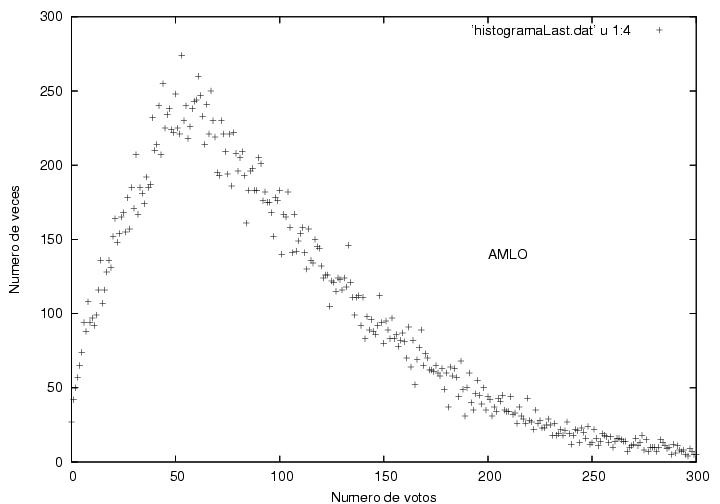
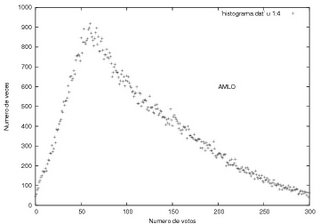 El caso de AMLO es un poco más complejo. EL corte en el origen se corresponde con lo que de hecho paso en las urnas, 0 votos en alrededor de 50 casillas. Lo extraño, no dice el profesor, el máximo de ocurrencias está por ahí de los 50 votos por casilla y se desvanece suavemente a la derecha, so far so good. El asunto está a la izquierda del máximo, "podría describirse muy bien por una burda línea recta" nos dice el profesor quien confiesa nunca haber visto una distribución probabilísta de ese tipo. A lo que se agrega que el máximo parece un pico, es decir, la frecuencia no se reduce suavemente para llegar a un máximo, sino que se llega a un máximo y decrece súbitamente. Nos dice el profe, "Esta curva podría describirse como una curva típica a la que se le cortó una parte"...Esto no significa que le 'cortaron' una parte, así se ve solamente. Ahora que, no será que justamente la parte 'cortada' corresponde a las actas que se incorporaron después?, aquellos famosos 3 millones de votos en actas con inconsistencias? pura especulación...
El caso de AMLO es un poco más complejo. EL corte en el origen se corresponde con lo que de hecho paso en las urnas, 0 votos en alrededor de 50 casillas. Lo extraño, no dice el profesor, el máximo de ocurrencias está por ahí de los 50 votos por casilla y se desvanece suavemente a la derecha, so far so good. El asunto está a la izquierda del máximo, "podría describirse muy bien por una burda línea recta" nos dice el profesor quien confiesa nunca haber visto una distribución probabilísta de ese tipo. A lo que se agrega que el máximo parece un pico, es decir, la frecuencia no se reduce suavemente para llegar a un máximo, sino que se llega a un máximo y decrece súbitamente. Nos dice el profe, "Esta curva podría describirse como una curva típica a la que se le cortó una parte"...Esto no significa que le 'cortaron' una parte, así se ve solamente. Ahora que, no será que justamente la parte 'cortada' corresponde a las actas que se incorporaron después?, aquellos famosos 3 millones de votos en actas con inconsistencias? pura especulación...
Veamos ahora la de Calderón:
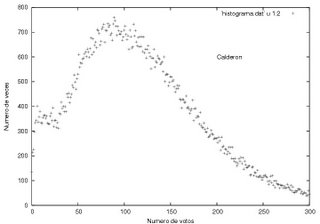 La de Calderón, nos dice el profe, es la más atípica de todas las distribuciones. Tiene un máximo muy 'ancho', lo cual es simplemente curioso. Lo raro está en el 'máximo local' alrededor de los 15 votos, que decrece abrubtamente cortando el eje en una sola casilla (o eso parece). El profe encontró que esta anomalía se debe principalmente a las útimas actas procesadas, entonces, si graficamos (bueno, yo no tuve nada que ver, así que no hay un 'graficamos', sino un 'graficaron') la frecuencia del número de votos por casilla sólo para las últimas 30 mil actas procesadas, en el caso de Calderón tenemos:
La de Calderón, nos dice el profe, es la más atípica de todas las distribuciones. Tiene un máximo muy 'ancho', lo cual es simplemente curioso. Lo raro está en el 'máximo local' alrededor de los 15 votos, que decrece abrubtamente cortando el eje en una sola casilla (o eso parece). El profe encontró que esta anomalía se debe principalmente a las útimas actas procesadas, entonces, si graficamos (bueno, yo no tuve nada que ver, así que no hay un 'graficamos', sino un 'graficaron') la frecuencia del número de votos por casilla sólo para las últimas 30 mil actas procesadas, en el caso de Calderón tenemos:

Lo primero que salta es la gran diferencia en la distribución de frecuencias entre las últimas 30 mil actas y el total de actas. Uno esperaría una distribución similar aunque quizás con una dispersión mayor. En cambio, nos dice el profe, "Estos datos tienen la forma típica que corresponde a la suma de dos distribuciones distintas, cada una con sus propias características". Lo curioso es ver que es sólo la distribución de Calderon en las últimas 30 mil actas procesadas la que se comporta visiblemente distinta a la distribución total. En los caso de AMLO y Madrazo, tenemos:
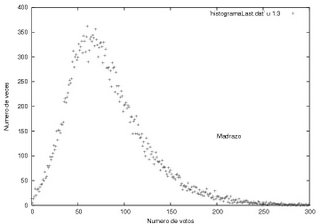
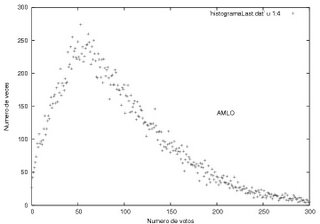
Las distribuciones de frecuencias para ambos candidatos para las últimas 30 mil actas procesadas son casi idénticas a aquellas con la totalidad de actas. Las diferencias son sutiles. En primer lugar, como esperaríamos la dispersión es un poco mayor. En segundo lugar, el máximo de Madrazo está un poco más a la derecha, esto es, Madrazo recibió más votos en más casillas al final del proceso. Finalmente, la gráfica para AMLO es idéntica a la de la totalidad de actas.
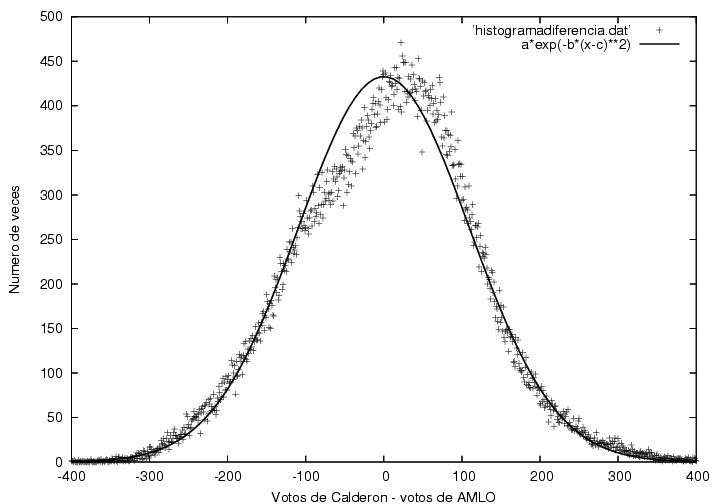
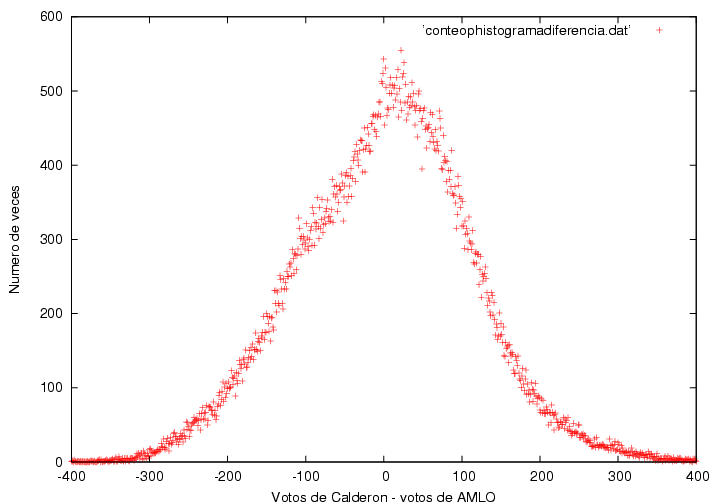
Quizás la gráfica más determinante en la página del profe (perdón por el exceso de confianza, pero es resultado de una tarde dedicada a la lectura de su página) es la figura 21.5, en ella se presenta la distribución de la diferencia de votos entre Calderón y AMLO:
 Por supuesto, a la derecha del cero tenemos las actas en las que Calderón superó a AMLO y la frecuencia de dicha ventaja, a la izquierda las actas en las que AMLO superó a Calderón y la frecuencia de la ventaja específica. El máximo, esto la frecuencia más común, se encuentra alrededor del cero, lo más común fue pues una ventaja muy cercana a cero. Lo raro está claro cuando uno ver la curva a partir de frecuencias superiores a las 250 actas. El profe comparó la curva observada con una curva ajustada gaussiana ("N=A exp(-B(V-C)^2), donde N representa el numero de veces que Calderón le llevo V votos de ventaja a AMLO y A= 432.819+/- 4.352, B = 4.15445x10^{-05} +/- 3.944x10^{-07} y C = 0.126841+/- 0.3256 son los parámetros del ajuste"). El ajuste es bastante bueno en las frecuencias bajas, pero en la parte superior de la curva el ajuste es bastante malo. La distorsión es muy grande. El profe concluye:
Por supuesto, a la derecha del cero tenemos las actas en las que Calderón superó a AMLO y la frecuencia de dicha ventaja, a la izquierda las actas en las que AMLO superó a Calderón y la frecuencia de la ventaja específica. El máximo, esto la frecuencia más común, se encuentra alrededor del cero, lo más común fue pues una ventaja muy cercana a cero. Lo raro está claro cuando uno ver la curva a partir de frecuencias superiores a las 250 actas. El profe comparó la curva observada con una curva ajustada gaussiana ("N=A exp(-B(V-C)^2), donde N representa el numero de veces que Calderón le llevo V votos de ventaja a AMLO y A= 432.819+/- 4.352, B = 4.15445x10^{-05} +/- 3.944x10^{-07} y C = 0.126841+/- 0.3256 son los parámetros del ajuste"). El ajuste es bastante bueno en las frecuencias bajas, pero en la parte superior de la curva el ajuste es bastante malo. La distorsión es muy grande. El profe concluye:
"notamos que su centroide está desplazado una distancia muy pequeña hacia la derecha, es decir, que en promedio Calderón le hubiera ganado a AMLO en 0.1 votos por casilla si la distribución hubiese sido la gaussiana ajustada arriba, i.e., hubiera ganado la elección por 10,000+/- 30,000 votos aproximadamente. Sin embargo, su ventaja fue mucho mayor gracias a la deformación en la cima de la distribución. La distribución tiene un cambio discontinuo de pendiente cerca de V=-100. ¿Por qué la distribución es aproximadamente gaussiana en la mayor parte del intervalo? ¿Por qué la distorsión en la parte alta de dicha distribución? ¿Por qué el cambio de pendiente es abrupto al llegar a dicha distorsión?"
Noten que la 'distorsión' empieza en el 'cruce' de una ventaja de AMLO un poco menor a los 100 votos y la frecuencia de dicha ventaja un poco por debajo de las 350 veces...
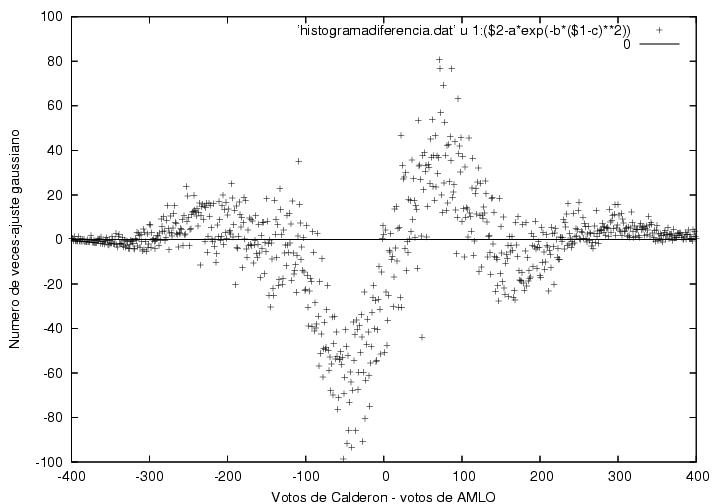
Para cuantificar la contribución de estas distorsiones en la distribución 'esperada', el profe graficó la diferencia entre los datos del PREP y la curva ajustada:
 Nótese que cuando la ventaja a favor de AMLO o Calderón es de más de 100 votos, los datos del PREP se ajustan a lo esperado por la curva ajustada. ¿O sea cómo?: "Sin embargo, en la región entre -100 y 0 los datos están sistemáticamente desplazados hacia abajo y entre 0 y 100 están sistemáticamente desplazados hacia arriba, con un mínimo cerca de -50 y un máximo cercano a 80. Es decir, hay menos casillas en las que AMLO gano por poco que las que seguirían de la distribución normal, y hay más casillas donde Calderón ganó por pocos votos que las que predice la distribución normal." Claro que esto puede deberse a que en la realidad (esa rara realidad), en las casillas 'competidas', los votantes apoyaron a Calderón más que a AMLO y que la frecuencia de estas casillas y los votos en ellas emitidos tuvieron de hecho un comportamiento distinto al resto (si alguien tiene una mejor intuición sobre esto compartanlo!). Ahora: "La contribución de la región entre -100 y 100 se puede estimar de multiplicar el tamaño de la anomalía por el número de votos involucrado y sumar dentro de la misma región, y conduce a una ventaja de 357,000 a favor de Calderón por encima de AMLO. ¿Cual es el origen de la bajada y subida en esta figura?"...
Nótese que cuando la ventaja a favor de AMLO o Calderón es de más de 100 votos, los datos del PREP se ajustan a lo esperado por la curva ajustada. ¿O sea cómo?: "Sin embargo, en la región entre -100 y 0 los datos están sistemáticamente desplazados hacia abajo y entre 0 y 100 están sistemáticamente desplazados hacia arriba, con un mínimo cerca de -50 y un máximo cercano a 80. Es decir, hay menos casillas en las que AMLO gano por poco que las que seguirían de la distribución normal, y hay más casillas donde Calderón ganó por pocos votos que las que predice la distribución normal." Claro que esto puede deberse a que en la realidad (esa rara realidad), en las casillas 'competidas', los votantes apoyaron a Calderón más que a AMLO y que la frecuencia de estas casillas y los votos en ellas emitidos tuvieron de hecho un comportamiento distinto al resto (si alguien tiene una mejor intuición sobre esto compartanlo!). Ahora: "La contribución de la región entre -100 y 100 se puede estimar de multiplicar el tamaño de la anomalía por el número de votos involucrado y sumar dentro de la misma región, y conduce a una ventaja de 357,000 a favor de Calderón por encima de AMLO. ¿Cual es el origen de la bajada y subida en esta figura?"...
Pasemos ahora al conteo distrital.
Hay que señalar en primer lugar que se trata de datos distintos. Hay 13,501 actas que no se habían incluído en el PREP y cuya distribución de votos fue: FCH 31.02%, RM 30.86% y AMLO 35.59%. 4.5% de ventaja para AMLO, uno hubiera esperado que la probabilidad de cometer errores se distribuyera uniformemente entre la población...
Empecemos por ver las frecuencias en el número de votos obtenidos por los tres candidatos por acta procesada:
 Como ven, la distribución de frecuencias del conteo distrital parece ser indéntico al del PREP. La gráfica muestra las mismas peculiaridades de las primeras tres que incluí en este texto. Como esperaríamos, la dispersión de los datos es menor, lo que permite identificar que "La anomalía en la curva de Calderón muestra ahora un mínimo muy claro en 26 votos 420 actas y una subida sistemática hasta un máximo en 6 votos con 560 casillas". Nuevamente, estas son cosas que pueden pasar en la realidad, son posibles, aunque poco probables.
Como ven, la distribución de frecuencias del conteo distrital parece ser indéntico al del PREP. La gráfica muestra las mismas peculiaridades de las primeras tres que incluí en este texto. Como esperaríamos, la dispersión de los datos es menor, lo que permite identificar que "La anomalía en la curva de Calderón muestra ahora un mínimo muy claro en 26 votos 420 actas y una subida sistemática hasta un máximo en 6 votos con 560 casillas". Nuevamente, estas son cosas que pueden pasar en la realidad, son posibles, aunque poco probables.
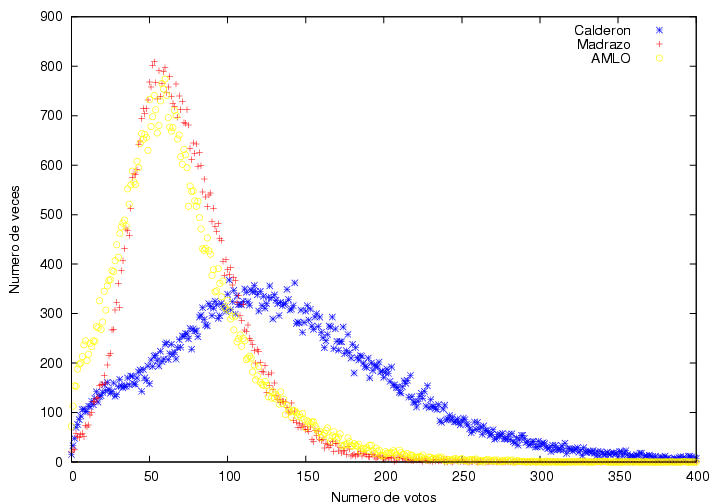
Ahora, el profe hace un ejercicio muy interesante: dividir la distribución de frecuencias regionalmente. Así, grafica para el norte (Aguascalientes, Baja California, Baja California Sur, Coahuila, Colima, Chihuahua, Durango, Guanajuato, Hidalgo, Jalisco, Nayarit, Nuevo León, Querétaro, San Luis, Sinaloa, Sonora, Tamaulipas y Zacatecas) y para el sur (Campeche, Chiapas, Distrito Federal, Guerrero, México, Michoacán, Morelos, Oaxaca, Puebla, Quintana Roo, Tabasco, Tlaxcala, Veracruz, Yucatán). Por tanto, la diferencia en los datos puede depender de la clasificación por regiones. De cualquier forma, los resultados son harto reveladores. Veamos el norte:
 Nada demasiado revelador. Tanto Madrazo como AMLO muestran que la mayor frecuencia se corresponde a actas en las que obtuvieron alrededor de 50 votos, mientras que en el caso de Calderón se encuentra en actas en las que obtuvo alrededor de 120 votos. Claramente, el norte fue ganado por Calderón. Ahora, veamos el sur:
Nada demasiado revelador. Tanto Madrazo como AMLO muestran que la mayor frecuencia se corresponde a actas en las que obtuvieron alrededor de 50 votos, mientras que en el caso de Calderón se encuentra en actas en las que obtuvo alrededor de 120 votos. Claramente, el norte fue ganado por Calderón. Ahora, veamos el sur:
 La frecuencia de votos de Madrazo se mantiene similar, con un poco más de actas con más de 100 votos para él. La distirbución de AMLO se parece ahora a la que tenía Calderón en el norte, aunque su mayor frecuencia está muy cerca de los 150 votos por acta. De nueva cuenta, es la curva de frecuencias de Calderón la del comportamiento extraño.
La frecuencia de votos de Madrazo se mantiene similar, con un poco más de actas con más de 100 votos para él. La distirbución de AMLO se parece ahora a la que tenía Calderón en el norte, aunque su mayor frecuencia está muy cerca de los 150 votos por acta. De nueva cuenta, es la curva de frecuencias de Calderón la del comportamiento extraño.
Si comparamos las distribuciones de frecuencias totales, de AMLO, de Calderón y de la suma de ambos:
 "A pesar de que las distribuciones correspondientes a Calderón y a AMLO son muy extrañas, la distribución de votos totales y de votos válidos las cuales contienen datos de ambos candidatos parecen ser normales. Incluso, la distribución para la suma de votos de Calderón+AMLO también parece ser normal, como muestra la figura. Tal parece que las peculiaridades de ambas distribuciones se cancelan una a la otra. Parafraseando a Gerardo (Horvilleur), ¿por qué habría una relación como esta entre dos variables, las cuales son más o menos independientes ya que los que no votaron por el PRD no estaban obligados a votar por el PAN: había otras opciones?" Pero, ¿Había en verdad otras opciones?...
"A pesar de que las distribuciones correspondientes a Calderón y a AMLO son muy extrañas, la distribución de votos totales y de votos válidos las cuales contienen datos de ambos candidatos parecen ser normales. Incluso, la distribución para la suma de votos de Calderón+AMLO también parece ser normal, como muestra la figura. Tal parece que las peculiaridades de ambas distribuciones se cancelan una a la otra. Parafraseando a Gerardo (Horvilleur), ¿por qué habría una relación como esta entre dos variables, las cuales son más o menos independientes ya que los que no votaron por el PRD no estaban obligados a votar por el PAN: había otras opciones?" Pero, ¿Había en verdad otras opciones?...
Veamos ahora la parte más interesante, ¿se acuerdan de la distribución de frecuencias en la diferencia de votos entre Calderón y AMLO? Esto es, la distribución del número de veces en que cada candidatos superó al otro por V votos?. Bueno, veamos como se comporta en el conteo:

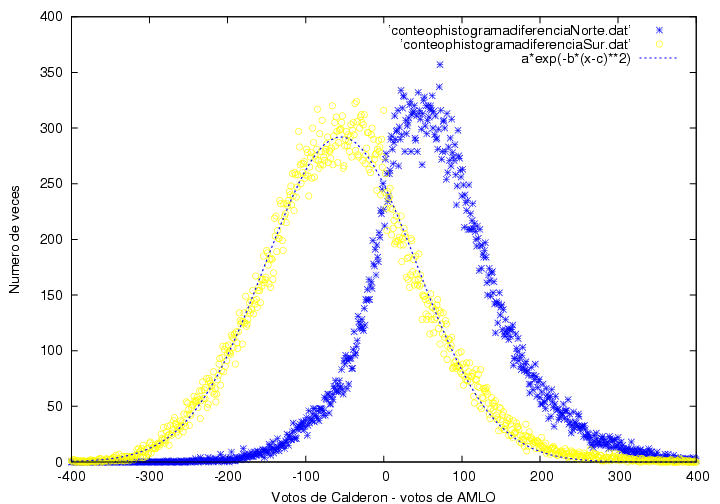
De nueva cuenta, tenemos el comportamiento anómalo en la frecuencia, en este caso por encima de 350, en el que la curva tiene un cambio brusco en su tendencia, que se corresponde a las actas en las que AMLO tiene una ventaja entre 50 y 0 votos. Si comparamos esta distribución para las dos regiones del país:

La curva nacional es anómala por que es la suma de dos curvas con comportamientos diferentes. Mientras que la curva correspondiente al sur (sí, la amarilla), tiene un muy buen ajuste con la curva gaussiana esperada, la curva del norte tiene un comportamiento extraño. Si las vemos empalmadas:
 ¿Qué es esto? Bueno, pues intuitivamente nos dice que en norte, y sólo en el norte, la frecuencia de votos de uno de los candidatos crece repentinamente entre los 100 y los 0 votos a favor. El candidato es AMLO. Esto significa que en el norte del país conforme la elección por casilla se tornaba más competida, la frecuencia de votos de ventaja por casilla para AMLO se redujo más rápido de lo esperado: "Los astrónomos reconocerán en la curva del Norte el llamado Perfil P Cisne (según Gloria Koenigsberger), correspondiente al espectro que describe el color de la luz proveniente de ciertas estrellas cuya radiación es selectivamente absorbida por el viento estelar." Selectivamente absorbida...El punto es saber el origen de esta 'absorsión selectiva'; esto es, el origen de la anomalía en la distribución de frecuencias fue producto de una distribución anómala de preferencias dentro de las secciones (así se portaron los electores) o si fue un sesgo de conteo y/o procesamiento...No sabemos.
¿Qué es esto? Bueno, pues intuitivamente nos dice que en norte, y sólo en el norte, la frecuencia de votos de uno de los candidatos crece repentinamente entre los 100 y los 0 votos a favor. El candidato es AMLO. Esto significa que en el norte del país conforme la elección por casilla se tornaba más competida, la frecuencia de votos de ventaja por casilla para AMLO se redujo más rápido de lo esperado: "Los astrónomos reconocerán en la curva del Norte el llamado Perfil P Cisne (según Gloria Koenigsberger), correspondiente al espectro que describe el color de la luz proveniente de ciertas estrellas cuya radiación es selectivamente absorbida por el viento estelar." Selectivamente absorbida...El punto es saber el origen de esta 'absorsión selectiva'; esto es, el origen de la anomalía en la distribución de frecuencias fue producto de una distribución anómala de preferencias dentro de las secciones (así se portaron los electores) o si fue un sesgo de conteo y/o procesamiento...No sabemos.
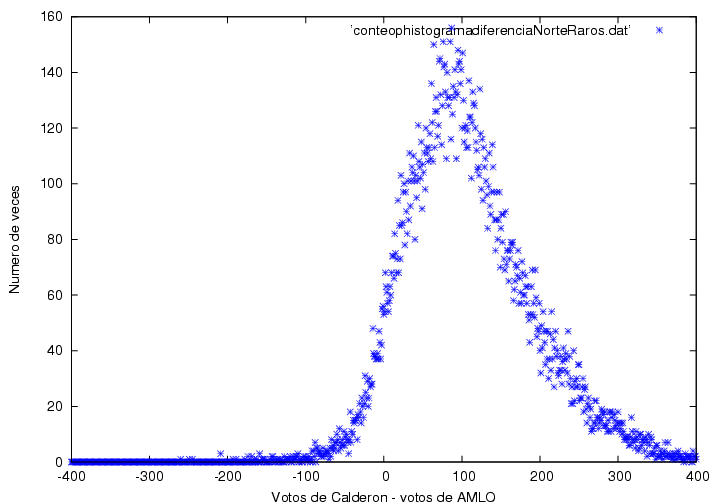
Lo que sí sabemos es que las anomalías norteñas se deben básicamente a 4 estados: Chihuahua, Guanajuato, Jalisco y Nuevo León. Nótese (cosa que el profe parece no tomar en consideración) que 2 de estos 4 estados tuvieron elecciones locales para gobernador concurrentes (Jalisco y Guanajuato), mientras que en Nuevo León hubo elecciones locales para el Congreso Estatal y las alcaldías (Gracias a Valdemar Díaz por hacerme notar esto). Si vemos la distribución de frecuencias para estos estados:

Se trata de una distribución que el profe llama "Completamente anómala", es muy asimétrica y tiene una enorme dispersión en torno al punto máximo. AMLO ganó muy pocas casillas, la mayoría de ellas por muy muy pocos votos. En cambio, Calderón ganó muchas casillas, la mayoría de ellas por alrededor de 100 votos. Lo verdaderamente notorio es que la distribución de frecuencias de la distancia entre los votos de Calderón y AMLO para el resto de los estados del norte (excluyendo a los 4 estados de arriba) tiene un comportamiento mucho menos anómalo y se ajusta mucho mejor al comportamiento esperado:
 El profe concluye:
El profe concluye:
" A partir de un análisis de los datos que el PREP volvió públicos, he encontrado, con ayuda de muchos colegas y de colaboradores que me son aún desconocidos, una larguísima serie de resultados que, a mi parecer, son anómalos y demandan una explicación detallada. Quizás haya expertos en elecciones y expertos en estadística que puedan ofrecer dicha explicación, o quizás sea necesario esperar el desarrollo de investigaciones científicas detalladas sobre esta elección; sin duda, investigaciones conclusivas de este tipo requerirán mucho tiempo en llevarse a cabo. Quizás no haya problemas con el PREP y las anomalías que he señalado no lo sean en realidad. Sin embargo, mientras no se realicen las investigaciones a que me he referido y no veamos los resultados o hasta que nos aclare algún experto nuestras dudas de manera convincente, y con base en la información que he logrado recopilar y los análisis que he logrado realizar, considero que es razonable sospechar que pudo haber habido una manipulación de los resultados reportados por el PREP."
La conclusión es pues que la distribución de frecuencias de votos, independientemente del momento de su inclusión en el PREP o en el Conteo Distrital, presentan comportamientos probabilísticos anómalos, particularmente para los casos de AMLO y Calderón, que parecen darle una ventaja electoral al segundo. ¿Es esto una señal de fraude electoral? La única respuesta posible es que no lo sabemos. Tampoco sabemos si estas anomalías estadísticas tienen su origen en la generación (el momento de votar), en el cómputo (dentro de las juntas distritales) o en el procesamiento de los datos (la agregación y publicación por parte del IFE).
Queda bastante por hacer, por lo pronto hay tres obvias: 1) ver el arribo temporal de las actas por distrito (sugerencia del siempre sabio Marco Morales), 2) ver la distribución de frecuencias por porcentajes y no por diferencias en votos, 3) comparar las distribuciones entre estados con elecciones concurrentes (todos estados con preferencias más panistas que perredistas, con excepción del Distrito Federal) y estados en los que hubo únicamente elecciones federales.
Hasta haber jugado con los datos y evaluar estas tres opciones...nos vemos.
Creo que se debe más a mi necesidad de entender que de explicar. Podría escribir sobre asuntos más personales, más emocionales digamos, que de esos sobran después del 2 de julio. Los por qués itinerantes. ¿Por qué voté por López Obrador? ¿Por qué quizás no lo haría nuevamente? ¿Por qué, entre el pecho y la cabeza, se me vuelven a atorar algunas dudas? ¿Por qué escucho el discurso de López Obrador y siento esta pesadéz estomacal? ¿Por qué los discursos excedidos de acusasiones y carentes de argumentos convincentes? ¿Por qué me irrita la cobardía de unas manos que en la madrugada destruyen la opinión de quienes, equivocados o no, manifiestan sus sospechas sobre el proceso electoral? ¿Por qué coños estoy yo a las 12:34 a.m. pensando y escribiendo estas cosas?
Para mi fortuna creo que soy todavía el único lector de mi blog, así que eso me evalentona lo suficiente para seguirle. Van dos prevenciones de por medio. En primer lugar, no soy experto en estadística, mucho menos en teoría de probabilidades. En segundo lugar, los datos aquí presentados, no son propios, pertenecen a una página generada por el Dr. Luis Mochán, investigador y físico de la UNAM, quien en un tono, me parece, harto prudente, presenta algunas cuestiones interesantes respecto al comportamiento de los datos generados mediante el PREP y el Conteo Distrital.
Dicho esto, empecemos (para ver mejor las gráficas, den click sobre ellas).
Primero el PREP.
Me salto las gráficas iniciales y empiezo por la figura 5 que grafica la distribución en la diferencia de votos entre Calderón y AMLO contra la acumulación de actas acumuladas:
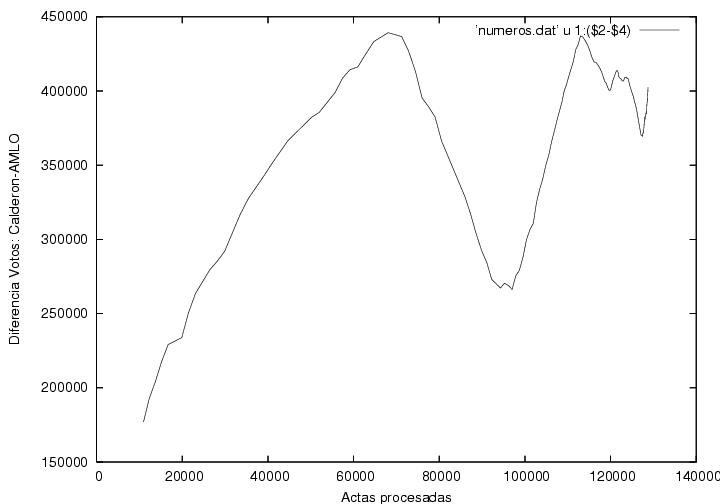 Aquí lo peculiar es el cambio abrubto entre tendencias. Por supuesto, esperamos fluctuaciones dado el timing de arribo de las actas a lo largo de todo el proceso de conteo, no necesariamente estos cortes tan dramáticos. ¿Se parece esto a lo que uno esperaría? Primero debemos señalar que Madrazo se encuentra ausente de esta medición. Segundo, no sabemos que tanto se parece esto a una distribución esperada.
Aquí lo peculiar es el cambio abrubto entre tendencias. Por supuesto, esperamos fluctuaciones dado el timing de arribo de las actas a lo largo de todo el proceso de conteo, no necesariamente estos cortes tan dramáticos. ¿Se parece esto a lo que uno esperaría? Primero debemos señalar que Madrazo se encuentra ausente de esta medición. Segundo, no sabemos que tanto se parece esto a una distribución esperada.La segunda gráfica muestra la acumulación de votos contra la acumulación de actas procesadas hasta 70,000:
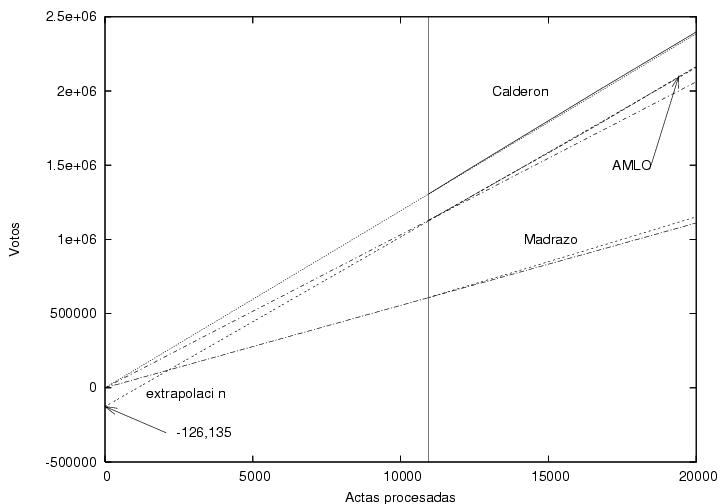 Aquí el tema es el comportamiento de extrapolaciones. Lo que hacen es ver el comportamiento esperado hacia atrás y hacia adeñante de la acumulación de votos con base en el comportamiento observado en el rango de 10 mil a 20 mil actas procesadas. En el caso de Calderón el ajuste es casi perfecto entre la línea de extrapolación y la línea observada. En el caso de Madrazo hay un pequeño sesgo positivo de la línea observada, esto significa simplemente que Madrazo acumuló más votos de 'lo esperado' hacia el final del proceso, lo que se ajusta a la intuición del voto rural priísta que siempre llega un poco más tarde. El caso de AMLO es el más interesante. En ambos lados la línea real y la línea de extrapolación no se ajusta. Hacia la derecha la línea real tiene un sesgo negativo, eso bien puede decir que las ganancias reales de Madrazo fueron las pérdidas 'no esperadas' de AMLO. Lo notorio es hacia la izquiera, la de AMLO es la única extrapolación hacia el origen que NO CORTA EN CERO, sino en -126, 135 votos. ¿Esto que significa? una posibilidad es que contrario a lo esperado, las últimas casillas reducieron su apoyo a AMLO, y esto sucedió además monotónicamente, o bien, como lo frasea el profesor Mochán: " En un escenario de mucha especulación sobre conspiraciones, estos datos podrían interpretarse de la siguiente manera: Pareciera haberse restado un voto a favor de AMLO por cada una de las 130,000 casillas durante la acumulación de los resultados. Seguramente, se podrían encontrar otras explicaciones. Será interesante saber por qué el voto de las primeras 10,000 casillas fue tan distinto al de las 60,000 casillas subsiguientes..." Demasiada especulación supongo. Pero sigamos.
Aquí el tema es el comportamiento de extrapolaciones. Lo que hacen es ver el comportamiento esperado hacia atrás y hacia adeñante de la acumulación de votos con base en el comportamiento observado en el rango de 10 mil a 20 mil actas procesadas. En el caso de Calderón el ajuste es casi perfecto entre la línea de extrapolación y la línea observada. En el caso de Madrazo hay un pequeño sesgo positivo de la línea observada, esto significa simplemente que Madrazo acumuló más votos de 'lo esperado' hacia el final del proceso, lo que se ajusta a la intuición del voto rural priísta que siempre llega un poco más tarde. El caso de AMLO es el más interesante. En ambos lados la línea real y la línea de extrapolación no se ajusta. Hacia la derecha la línea real tiene un sesgo negativo, eso bien puede decir que las ganancias reales de Madrazo fueron las pérdidas 'no esperadas' de AMLO. Lo notorio es hacia la izquiera, la de AMLO es la única extrapolación hacia el origen que NO CORTA EN CERO, sino en -126, 135 votos. ¿Esto que significa? una posibilidad es que contrario a lo esperado, las últimas casillas reducieron su apoyo a AMLO, y esto sucedió además monotónicamente, o bien, como lo frasea el profesor Mochán: " En un escenario de mucha especulación sobre conspiraciones, estos datos podrían interpretarse de la siguiente manera: Pareciera haberse restado un voto a favor de AMLO por cada una de las 130,000 casillas durante la acumulación de los resultados. Seguramente, se podrían encontrar otras explicaciones. Será interesante saber por qué el voto de las primeras 10,000 casillas fue tan distinto al de las 60,000 casillas subsiguientes..." Demasiada especulación supongo. Pero sigamos.Me salto varias gráfica y llego a otro grupo interesante. Aquí se presentan los histogramas correspondientes a la frecuencia en el número de veces que un candidato obtuvo determinado número de votos. Esto es, por ejemplo en cuántas casillas Madrazo obtuvo 10 votos, en cuántas 11, en cuántas 12...Empecemos entonces con Madrazo:
 La distribución del voto por madrazo por acta es impecable, de "libro de texto" nos dice el profesor. Tiene 0 casillas con 0 votos, y se comporta normalmente. Ahora, la de AMLO:
La distribución del voto por madrazo por acta es impecable, de "libro de texto" nos dice el profesor. Tiene 0 casillas con 0 votos, y se comporta normalmente. Ahora, la de AMLO: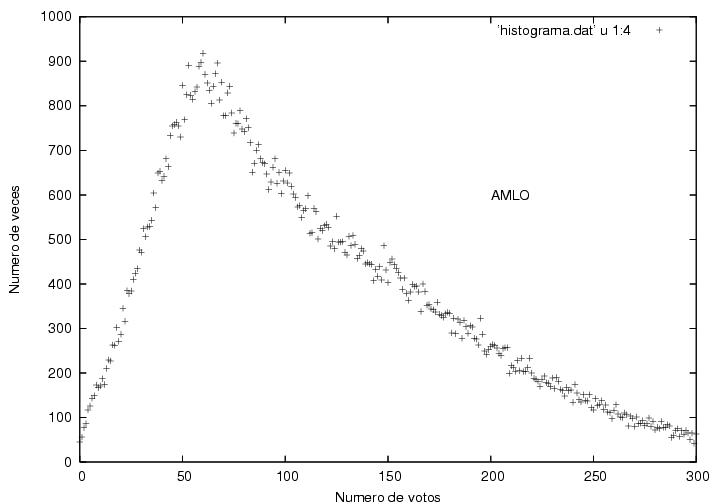 El caso de AMLO es un poco más complejo. EL corte en el origen se corresponde con lo que de hecho paso en las urnas, 0 votos en alrededor de 50 casillas. Lo extraño, no dice el profesor, el máximo de ocurrencias está por ahí de los 50 votos por casilla y se desvanece suavemente a la derecha, so far so good. El asunto está a la izquierda del máximo, "podría describirse muy bien por una burda línea recta" nos dice el profesor quien confiesa nunca haber visto una distribución probabilísta de ese tipo. A lo que se agrega que el máximo parece un pico, es decir, la frecuencia no se reduce suavemente para llegar a un máximo, sino que se llega a un máximo y decrece súbitamente. Nos dice el profe, "Esta curva podría describirse como una curva típica a la que se le cortó una parte"...Esto no significa que le 'cortaron' una parte, así se ve solamente. Ahora que, no será que justamente la parte 'cortada' corresponde a las actas que se incorporaron después?, aquellos famosos 3 millones de votos en actas con inconsistencias? pura especulación...
El caso de AMLO es un poco más complejo. EL corte en el origen se corresponde con lo que de hecho paso en las urnas, 0 votos en alrededor de 50 casillas. Lo extraño, no dice el profesor, el máximo de ocurrencias está por ahí de los 50 votos por casilla y se desvanece suavemente a la derecha, so far so good. El asunto está a la izquierda del máximo, "podría describirse muy bien por una burda línea recta" nos dice el profesor quien confiesa nunca haber visto una distribución probabilísta de ese tipo. A lo que se agrega que el máximo parece un pico, es decir, la frecuencia no se reduce suavemente para llegar a un máximo, sino que se llega a un máximo y decrece súbitamente. Nos dice el profe, "Esta curva podría describirse como una curva típica a la que se le cortó una parte"...Esto no significa que le 'cortaron' una parte, así se ve solamente. Ahora que, no será que justamente la parte 'cortada' corresponde a las actas que se incorporaron después?, aquellos famosos 3 millones de votos en actas con inconsistencias? pura especulación...Veamos ahora la de Calderón:
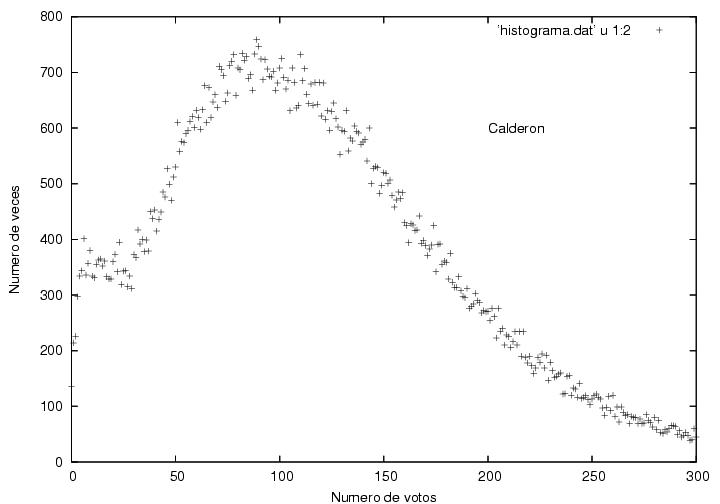 La de Calderón, nos dice el profe, es la más atípica de todas las distribuciones. Tiene un máximo muy 'ancho', lo cual es simplemente curioso. Lo raro está en el 'máximo local' alrededor de los 15 votos, que decrece abrubtamente cortando el eje en una sola casilla (o eso parece). El profe encontró que esta anomalía se debe principalmente a las útimas actas procesadas, entonces, si graficamos (bueno, yo no tuve nada que ver, así que no hay un 'graficamos', sino un 'graficaron') la frecuencia del número de votos por casilla sólo para las últimas 30 mil actas procesadas, en el caso de Calderón tenemos:
La de Calderón, nos dice el profe, es la más atípica de todas las distribuciones. Tiene un máximo muy 'ancho', lo cual es simplemente curioso. Lo raro está en el 'máximo local' alrededor de los 15 votos, que decrece abrubtamente cortando el eje en una sola casilla (o eso parece). El profe encontró que esta anomalía se debe principalmente a las útimas actas procesadas, entonces, si graficamos (bueno, yo no tuve nada que ver, así que no hay un 'graficamos', sino un 'graficaron') la frecuencia del número de votos por casilla sólo para las últimas 30 mil actas procesadas, en el caso de Calderón tenemos:
Lo primero que salta es la gran diferencia en la distribución de frecuencias entre las últimas 30 mil actas y el total de actas. Uno esperaría una distribución similar aunque quizás con una dispersión mayor. En cambio, nos dice el profe, "Estos datos tienen la forma típica que corresponde a la suma de dos distribuciones distintas, cada una con sus propias características". Lo curioso es ver que es sólo la distribución de Calderon en las últimas 30 mil actas procesadas la que se comporta visiblemente distinta a la distribución total. En los caso de AMLO y Madrazo, tenemos:

Las distribuciones de frecuencias para ambos candidatos para las últimas 30 mil actas procesadas son casi idénticas a aquellas con la totalidad de actas. Las diferencias son sutiles. En primer lugar, como esperaríamos la dispersión es un poco mayor. En segundo lugar, el máximo de Madrazo está un poco más a la derecha, esto es, Madrazo recibió más votos en más casillas al final del proceso. Finalmente, la gráfica para AMLO es idéntica a la de la totalidad de actas.
Quizás la gráfica más determinante en la página del profe (perdón por el exceso de confianza, pero es resultado de una tarde dedicada a la lectura de su página) es la figura 21.5, en ella se presenta la distribución de la diferencia de votos entre Calderón y AMLO:
 Por supuesto, a la derecha del cero tenemos las actas en las que Calderón superó a AMLO y la frecuencia de dicha ventaja, a la izquierda las actas en las que AMLO superó a Calderón y la frecuencia de la ventaja específica. El máximo, esto la frecuencia más común, se encuentra alrededor del cero, lo más común fue pues una ventaja muy cercana a cero. Lo raro está claro cuando uno ver la curva a partir de frecuencias superiores a las 250 actas. El profe comparó la curva observada con una curva ajustada gaussiana ("N=A exp(-B(V-C)^2), donde N representa el numero de veces que Calderón le llevo V votos de ventaja a AMLO y A= 432.819+/- 4.352, B = 4.15445x10^{-05} +/- 3.944x10^{-07} y C = 0.126841+/- 0.3256 son los parámetros del ajuste"). El ajuste es bastante bueno en las frecuencias bajas, pero en la parte superior de la curva el ajuste es bastante malo. La distorsión es muy grande. El profe concluye:
Por supuesto, a la derecha del cero tenemos las actas en las que Calderón superó a AMLO y la frecuencia de dicha ventaja, a la izquierda las actas en las que AMLO superó a Calderón y la frecuencia de la ventaja específica. El máximo, esto la frecuencia más común, se encuentra alrededor del cero, lo más común fue pues una ventaja muy cercana a cero. Lo raro está claro cuando uno ver la curva a partir de frecuencias superiores a las 250 actas. El profe comparó la curva observada con una curva ajustada gaussiana ("N=A exp(-B(V-C)^2), donde N representa el numero de veces que Calderón le llevo V votos de ventaja a AMLO y A= 432.819+/- 4.352, B = 4.15445x10^{-05} +/- 3.944x10^{-07} y C = 0.126841+/- 0.3256 son los parámetros del ajuste"). El ajuste es bastante bueno en las frecuencias bajas, pero en la parte superior de la curva el ajuste es bastante malo. La distorsión es muy grande. El profe concluye:"notamos que su centroide está desplazado una distancia muy pequeña hacia la derecha, es decir, que en promedio Calderón le hubiera ganado a AMLO en 0.1 votos por casilla si la distribución hubiese sido la gaussiana ajustada arriba, i.e., hubiera ganado la elección por 10,000+/- 30,000 votos aproximadamente. Sin embargo, su ventaja fue mucho mayor gracias a la deformación en la cima de la distribución. La distribución tiene un cambio discontinuo de pendiente cerca de V=-100. ¿Por qué la distribución es aproximadamente gaussiana en la mayor parte del intervalo? ¿Por qué la distorsión en la parte alta de dicha distribución? ¿Por qué el cambio de pendiente es abrupto al llegar a dicha distorsión?"
Noten que la 'distorsión' empieza en el 'cruce' de una ventaja de AMLO un poco menor a los 100 votos y la frecuencia de dicha ventaja un poco por debajo de las 350 veces...
Para cuantificar la contribución de estas distorsiones en la distribución 'esperada', el profe graficó la diferencia entre los datos del PREP y la curva ajustada:
 Nótese que cuando la ventaja a favor de AMLO o Calderón es de más de 100 votos, los datos del PREP se ajustan a lo esperado por la curva ajustada. ¿O sea cómo?: "Sin embargo, en la región entre -100 y 0 los datos están sistemáticamente desplazados hacia abajo y entre 0 y 100 están sistemáticamente desplazados hacia arriba, con un mínimo cerca de -50 y un máximo cercano a 80. Es decir, hay menos casillas en las que AMLO gano por poco que las que seguirían de la distribución normal, y hay más casillas donde Calderón ganó por pocos votos que las que predice la distribución normal." Claro que esto puede deberse a que en la realidad (esa rara realidad), en las casillas 'competidas', los votantes apoyaron a Calderón más que a AMLO y que la frecuencia de estas casillas y los votos en ellas emitidos tuvieron de hecho un comportamiento distinto al resto (si alguien tiene una mejor intuición sobre esto compartanlo!). Ahora: "La contribución de la región entre -100 y 100 se puede estimar de multiplicar el tamaño de la anomalía por el número de votos involucrado y sumar dentro de la misma región, y conduce a una ventaja de 357,000 a favor de Calderón por encima de AMLO. ¿Cual es el origen de la bajada y subida en esta figura?"...
Nótese que cuando la ventaja a favor de AMLO o Calderón es de más de 100 votos, los datos del PREP se ajustan a lo esperado por la curva ajustada. ¿O sea cómo?: "Sin embargo, en la región entre -100 y 0 los datos están sistemáticamente desplazados hacia abajo y entre 0 y 100 están sistemáticamente desplazados hacia arriba, con un mínimo cerca de -50 y un máximo cercano a 80. Es decir, hay menos casillas en las que AMLO gano por poco que las que seguirían de la distribución normal, y hay más casillas donde Calderón ganó por pocos votos que las que predice la distribución normal." Claro que esto puede deberse a que en la realidad (esa rara realidad), en las casillas 'competidas', los votantes apoyaron a Calderón más que a AMLO y que la frecuencia de estas casillas y los votos en ellas emitidos tuvieron de hecho un comportamiento distinto al resto (si alguien tiene una mejor intuición sobre esto compartanlo!). Ahora: "La contribución de la región entre -100 y 100 se puede estimar de multiplicar el tamaño de la anomalía por el número de votos involucrado y sumar dentro de la misma región, y conduce a una ventaja de 357,000 a favor de Calderón por encima de AMLO. ¿Cual es el origen de la bajada y subida en esta figura?"...Pasemos ahora al conteo distrital.
Hay que señalar en primer lugar que se trata de datos distintos. Hay 13,501 actas que no se habían incluído en el PREP y cuya distribución de votos fue: FCH 31.02%, RM 30.86% y AMLO 35.59%. 4.5% de ventaja para AMLO, uno hubiera esperado que la probabilidad de cometer errores se distribuyera uniformemente entre la población...
Empecemos por ver las frecuencias en el número de votos obtenidos por los tres candidatos por acta procesada:
 Como ven, la distribución de frecuencias del conteo distrital parece ser indéntico al del PREP. La gráfica muestra las mismas peculiaridades de las primeras tres que incluí en este texto. Como esperaríamos, la dispersión de los datos es menor, lo que permite identificar que "La anomalía en la curva de Calderón muestra ahora un mínimo muy claro en 26 votos 420 actas y una subida sistemática hasta un máximo en 6 votos con 560 casillas". Nuevamente, estas son cosas que pueden pasar en la realidad, son posibles, aunque poco probables.
Como ven, la distribución de frecuencias del conteo distrital parece ser indéntico al del PREP. La gráfica muestra las mismas peculiaridades de las primeras tres que incluí en este texto. Como esperaríamos, la dispersión de los datos es menor, lo que permite identificar que "La anomalía en la curva de Calderón muestra ahora un mínimo muy claro en 26 votos 420 actas y una subida sistemática hasta un máximo en 6 votos con 560 casillas". Nuevamente, estas son cosas que pueden pasar en la realidad, son posibles, aunque poco probables.Ahora, el profe hace un ejercicio muy interesante: dividir la distribución de frecuencias regionalmente. Así, grafica para el norte (Aguascalientes, Baja California, Baja California Sur, Coahuila, Colima, Chihuahua, Durango, Guanajuato, Hidalgo, Jalisco, Nayarit, Nuevo León, Querétaro, San Luis, Sinaloa, Sonora, Tamaulipas y Zacatecas) y para el sur (Campeche, Chiapas, Distrito Federal, Guerrero, México, Michoacán, Morelos, Oaxaca, Puebla, Quintana Roo, Tabasco, Tlaxcala, Veracruz, Yucatán). Por tanto, la diferencia en los datos puede depender de la clasificación por regiones. De cualquier forma, los resultados son harto reveladores. Veamos el norte:
 Nada demasiado revelador. Tanto Madrazo como AMLO muestran que la mayor frecuencia se corresponde a actas en las que obtuvieron alrededor de 50 votos, mientras que en el caso de Calderón se encuentra en actas en las que obtuvo alrededor de 120 votos. Claramente, el norte fue ganado por Calderón. Ahora, veamos el sur:
Nada demasiado revelador. Tanto Madrazo como AMLO muestran que la mayor frecuencia se corresponde a actas en las que obtuvieron alrededor de 50 votos, mientras que en el caso de Calderón se encuentra en actas en las que obtuvo alrededor de 120 votos. Claramente, el norte fue ganado por Calderón. Ahora, veamos el sur: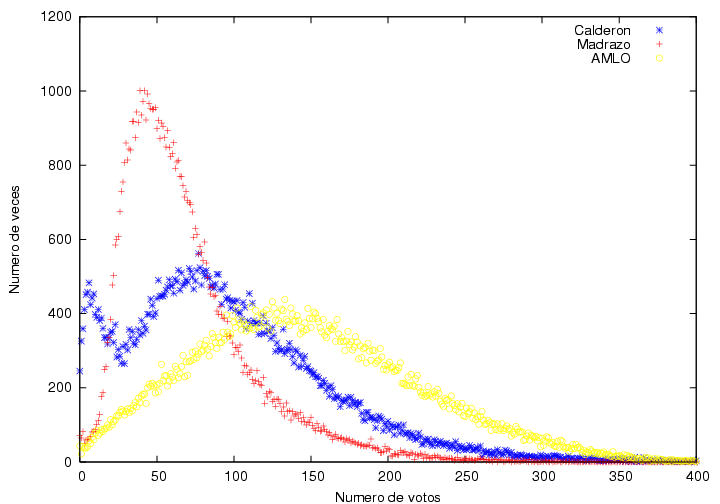 La frecuencia de votos de Madrazo se mantiene similar, con un poco más de actas con más de 100 votos para él. La distirbución de AMLO se parece ahora a la que tenía Calderón en el norte, aunque su mayor frecuencia está muy cerca de los 150 votos por acta. De nueva cuenta, es la curva de frecuencias de Calderón la del comportamiento extraño.
La frecuencia de votos de Madrazo se mantiene similar, con un poco más de actas con más de 100 votos para él. La distirbución de AMLO se parece ahora a la que tenía Calderón en el norte, aunque su mayor frecuencia está muy cerca de los 150 votos por acta. De nueva cuenta, es la curva de frecuencias de Calderón la del comportamiento extraño.Si comparamos las distribuciones de frecuencias totales, de AMLO, de Calderón y de la suma de ambos:
 "A pesar de que las distribuciones correspondientes a Calderón y a AMLO son muy extrañas, la distribución de votos totales y de votos válidos las cuales contienen datos de ambos candidatos parecen ser normales. Incluso, la distribución para la suma de votos de Calderón+AMLO también parece ser normal, como muestra la figura. Tal parece que las peculiaridades de ambas distribuciones se cancelan una a la otra. Parafraseando a Gerardo (Horvilleur), ¿por qué habría una relación como esta entre dos variables, las cuales son más o menos independientes ya que los que no votaron por el PRD no estaban obligados a votar por el PAN: había otras opciones?" Pero, ¿Había en verdad otras opciones?...
"A pesar de que las distribuciones correspondientes a Calderón y a AMLO son muy extrañas, la distribución de votos totales y de votos válidos las cuales contienen datos de ambos candidatos parecen ser normales. Incluso, la distribución para la suma de votos de Calderón+AMLO también parece ser normal, como muestra la figura. Tal parece que las peculiaridades de ambas distribuciones se cancelan una a la otra. Parafraseando a Gerardo (Horvilleur), ¿por qué habría una relación como esta entre dos variables, las cuales son más o menos independientes ya que los que no votaron por el PRD no estaban obligados a votar por el PAN: había otras opciones?" Pero, ¿Había en verdad otras opciones?...Veamos ahora la parte más interesante, ¿se acuerdan de la distribución de frecuencias en la diferencia de votos entre Calderón y AMLO? Esto es, la distribución del número de veces en que cada candidatos superó al otro por V votos?. Bueno, veamos como se comporta en el conteo:
De nueva cuenta, tenemos el comportamiento anómalo en la frecuencia, en este caso por encima de 350, en el que la curva tiene un cambio brusco en su tendencia, que se corresponde a las actas en las que AMLO tiene una ventaja entre 50 y 0 votos. Si comparamos esta distribución para las dos regiones del país:
La curva nacional es anómala por que es la suma de dos curvas con comportamientos diferentes. Mientras que la curva correspondiente al sur (sí, la amarilla), tiene un muy buen ajuste con la curva gaussiana esperada, la curva del norte tiene un comportamiento extraño. Si las vemos empalmadas:
 ¿Qué es esto? Bueno, pues intuitivamente nos dice que en norte, y sólo en el norte, la frecuencia de votos de uno de los candidatos crece repentinamente entre los 100 y los 0 votos a favor. El candidato es AMLO. Esto significa que en el norte del país conforme la elección por casilla se tornaba más competida, la frecuencia de votos de ventaja por casilla para AMLO se redujo más rápido de lo esperado: "Los astrónomos reconocerán en la curva del Norte el llamado Perfil P Cisne (según Gloria Koenigsberger), correspondiente al espectro que describe el color de la luz proveniente de ciertas estrellas cuya radiación es selectivamente absorbida por el viento estelar." Selectivamente absorbida...El punto es saber el origen de esta 'absorsión selectiva'; esto es, el origen de la anomalía en la distribución de frecuencias fue producto de una distribución anómala de preferencias dentro de las secciones (así se portaron los electores) o si fue un sesgo de conteo y/o procesamiento...No sabemos.
¿Qué es esto? Bueno, pues intuitivamente nos dice que en norte, y sólo en el norte, la frecuencia de votos de uno de los candidatos crece repentinamente entre los 100 y los 0 votos a favor. El candidato es AMLO. Esto significa que en el norte del país conforme la elección por casilla se tornaba más competida, la frecuencia de votos de ventaja por casilla para AMLO se redujo más rápido de lo esperado: "Los astrónomos reconocerán en la curva del Norte el llamado Perfil P Cisne (según Gloria Koenigsberger), correspondiente al espectro que describe el color de la luz proveniente de ciertas estrellas cuya radiación es selectivamente absorbida por el viento estelar." Selectivamente absorbida...El punto es saber el origen de esta 'absorsión selectiva'; esto es, el origen de la anomalía en la distribución de frecuencias fue producto de una distribución anómala de preferencias dentro de las secciones (así se portaron los electores) o si fue un sesgo de conteo y/o procesamiento...No sabemos.Lo que sí sabemos es que las anomalías norteñas se deben básicamente a 4 estados: Chihuahua, Guanajuato, Jalisco y Nuevo León. Nótese (cosa que el profe parece no tomar en consideración) que 2 de estos 4 estados tuvieron elecciones locales para gobernador concurrentes (Jalisco y Guanajuato), mientras que en Nuevo León hubo elecciones locales para el Congreso Estatal y las alcaldías (Gracias a Valdemar Díaz por hacerme notar esto). Si vemos la distribución de frecuencias para estos estados:
Se trata de una distribución que el profe llama "Completamente anómala", es muy asimétrica y tiene una enorme dispersión en torno al punto máximo. AMLO ganó muy pocas casillas, la mayoría de ellas por muy muy pocos votos. En cambio, Calderón ganó muchas casillas, la mayoría de ellas por alrededor de 100 votos. Lo verdaderamente notorio es que la distribución de frecuencias de la distancia entre los votos de Calderón y AMLO para el resto de los estados del norte (excluyendo a los 4 estados de arriba) tiene un comportamiento mucho menos anómalo y se ajusta mucho mejor al comportamiento esperado:
 El profe concluye:
El profe concluye:" A partir de un análisis de los datos que el PREP volvió públicos, he encontrado, con ayuda de muchos colegas y de colaboradores que me son aún desconocidos, una larguísima serie de resultados que, a mi parecer, son anómalos y demandan una explicación detallada. Quizás haya expertos en elecciones y expertos en estadística que puedan ofrecer dicha explicación, o quizás sea necesario esperar el desarrollo de investigaciones científicas detalladas sobre esta elección; sin duda, investigaciones conclusivas de este tipo requerirán mucho tiempo en llevarse a cabo. Quizás no haya problemas con el PREP y las anomalías que he señalado no lo sean en realidad. Sin embargo, mientras no se realicen las investigaciones a que me he referido y no veamos los resultados o hasta que nos aclare algún experto nuestras dudas de manera convincente, y con base en la información que he logrado recopilar y los análisis que he logrado realizar, considero que es razonable sospechar que pudo haber habido una manipulación de los resultados reportados por el PREP."
La conclusión es pues que la distribución de frecuencias de votos, independientemente del momento de su inclusión en el PREP o en el Conteo Distrital, presentan comportamientos probabilísticos anómalos, particularmente para los casos de AMLO y Calderón, que parecen darle una ventaja electoral al segundo. ¿Es esto una señal de fraude electoral? La única respuesta posible es que no lo sabemos. Tampoco sabemos si estas anomalías estadísticas tienen su origen en la generación (el momento de votar), en el cómputo (dentro de las juntas distritales) o en el procesamiento de los datos (la agregación y publicación por parte del IFE).
Queda bastante por hacer, por lo pronto hay tres obvias: 1) ver el arribo temporal de las actas por distrito (sugerencia del siempre sabio Marco Morales), 2) ver la distribución de frecuencias por porcentajes y no por diferencias en votos, 3) comparar las distribuciones entre estados con elecciones concurrentes (todos estados con preferencias más panistas que perredistas, con excepción del Distrito Federal) y estados en los que hubo únicamente elecciones federales.
Hasta haber jugado con los datos y evaluar estas tres opciones...nos vemos.
1 comentario:
Sr. Merino: le agradezco muchísimo tres cosas, 1)Que me haya mandado a leer, cosa indispensable para "entender" un poco más el asunto. Entender va entrecomillado, porque, entender, entender, lo que se dice entender, no lo logré mucho. La especialidad del profesor citado y la suya me lo impiden. 2)Agradezco también sus esfuerzos, de supongo muchas horas, porque supongo también a Ud. le asaltaron algunas dudas. Y me parece muy bien que personas con herramientas para el tratamiento del asunto, no se dejen ir por el cómodo "es imposible alterar los resultados del IFE". Eso es de inteligencias curiosas y críticas. No hay avance sin capacidad crítica. 3) El compromiso que manifiesta hasta donde es posible por el desarrollo de la investigación citada, y la suya propia.
Considéreme una fan
Publicar un comentario